그것은 파이썬으로 구현이 되겠지만 적어도 초기의 단계에서는 대신에 베이직이나 티클로 쓸 수가 있다. 우리가 더 복잡한 부분으로 이동함에 따라서 우리는 파이썬의 내장 데이타 구조들을 점점 더 많이 사용하게 될 것이고 그러므로, 티클은 여전히 선택사항일 수 있겠지만, 베이직을 사용하기는 더 어려워질 것이다. 결국 OO 의 모습은 파이썬에게만 적용될 것이다.
구현가능하지만 여전히 연습문제로 독자에게 남겨질 추가적인 사양은 다음과 같다:
import string
def numwords(s):
list = string.split(s)
return len(list)
inp = open("menu.txt","r")
total = 0
# accumulate totals for each line
for line in inp.readlines():
total = total + numwords(line)
print "File had %d words" % total
inp.close()
우리는 라인과 문자 계수기를 추가할 필요가 있다. 라인 계수기는 쉬운데 왜냐하면 우리가 각라인을 회돌이 시키고 단순히 그 회돌이의 각 반복에 증가하는 변수 하나만 필요하기 때문이다.
문자 계수기는 단지 약간 더 어렵다. 왜냐하면 우리는 단어의 리스트를 반복시켜서 그것들의 길이를 역시 또 다른 변수 하나에 추가할 수 있기 때문이다.
우리는 또한 그 프로그램을 명령어 라인으로부터 그 파일의 이름을 읽음으로써 혹은 만약 제공되지 않는다면, 사용자에게 그 파일의 이름을 요구함으로써 더욱 일반적인 목적으로 사용되도록 만들 필요가 있다. (대안적인 전략은 표준입력으로부터 읽는 것이다, 그것이 진짜 wc가 하는 것이다.)
그래서 최종 wc 는 다음과 같이 보인다:
import sys, string # Get the file name either from the commandline or the user if len(sys.argv) != 2: name = raw_input("Enter the file name: ") else: name = sys.argv[1] inp = open(name,"r") # initialise counters to zero; which also creates variables words = 0 lines = 0 chars = 0 for line in inp.readlines(): lines = lines + 1 # Break into a list of words and count them list = string.split(line) words = words + len(list) chars = len(line)# Use the original line length which includes spaces etc. print "%s has %d lines, %d words and %d characters" % (name, lines, words, chars) inp.close()
여러분이 유닉스의 wc 명령어에 익숙하다면 여러분은 그것을 와일드카드 파일이름으로 넘겨서 일치되는 모든 파일에 대한 정보뿐만 아니라 전체 합계에 대한 정보도 획득할 수 있다는 것을 알 것이다. 이 프로그램은 오직 직접적으로 주어지는 파일 이름만을 만족한다. 여러분이 그것을 확장하여 와일드 카드를 만족시키려면 glob 모듈을 살펴서 이름의 리스트를 만들고 그리고 단지 그 파일의 리스트를 반복하기만 하면 된다. 여러분은 각 파일을 위한 임시 카운터가 필요할 것이다 그리고는 전체 합계를 위하여 축적된 카운터가 필요할 것이다. 혹은 여러분은 대신에 사전을 사용할 수도 있다...
그것에 대하여 조금만 더 생각해 보면 우리가 단순하게 단어들과 구두점 문자들을 모은다면 우리는 후자를 분석하여 (우리가 구두점들의 관점에서 문장/절을 무엇으로 생각하는 지를 정의 함으로써) 문장들, 절 등등을 셀 수 있다는 것이 명백해진다.
이것은 우리가 그 파일에 대하여 한번만 반복할 필요가 있으며 그리고 그 구두점에 대하여 반복할 필요가 있다는 것을 뜻한다 - 훨씬 더 작은 리스트로.
그것을 의사-코드로 대충그려보자:
foreach line in file:
increment line count
if line empty:
increment paragraph count
split line into character groups
foreach character group:
increment group count
extract punctuation chars into a dictionary - {char:count}
if no chars left:
delete group
else: increment word count
sentence count = sum of('.', '?', '!')
clause count = sum of all punctuation (very poor definition...)
report paras, lines, sentences, clauses, groups, words.
foreach puntuation char:
report count
이것을 보면 우리는 대략 4개의 함수를 위와 같이 자연적인 그룹화를 사용하여 작성할 수 있을 것 같다.
이것의 도움으로 우리는 부분 혹은 전체를 재사용할 수 있는 모듈을 구축할 수 있다.
############################# # Module: grammar # Created: A.J. Gauld, 2000,8,12 # # Funtion: # counts paragraphs, lines, sentences, 'clauses', char groups, # words and punctuation for a prose like text file. It assumes # that sentences end with [.!?] and paragraphs have a blank line # between them. A 'clause' is simply a segment of sentence # separated by punctuation(braindead but maybe someday we'll # do better!) # # Usage: Basic usage takes a filename parameter and outputs all # stats. Its really intended that a second module use the # functions provided to produce more useful commands. ############################# import string, sys ############################ # initialise global variables para_count = 1 line_count, sentence_count, clause_count, word_count = 0,0,0,0 groups = [] alphas = string.letters + string.digits stop_tokens = ['.','?','!'] punctuation_chars = ['&','(',')','-',';',':',','] + stop_tokens for c in punctuation_chars: punctuation_counts[c] = 0 punctuation_counts = {} format = """%s contains: %d paragraphs, %d lines and %d sentences. These in turn contain %d clauses and a total of %d words.""" ############################ # Now define the functions that do the work def getCharGroups(infile): pass def getPunctuation(wordList): pass def reportStats(): print format % (sys.argv[1],para_count, line_count, sentence_count, clause_count, word_count) def Analyze(infile): getCharGroups(infile) getPunctuation(groups) reportStats() # Make it run if called from the command line (in which # case the 'magic' __name__ variable gets set to '__main__' if __name__ == "__main__": if len(sys.argv) != 2: print "Usage: python grammer.py <filename >" sys.exit() else: Document = open(sys.argv[1],"r") Analyze(Document)한개의 기다란 리스트에 모든 것을 보여주려고 노력하기 보다는 나는 이것을 주요점만 논의할 것이며 3개의 중요한 함수를 차례로 각각 살펴볼 것이다. 그렇지만 그 프로그램을 작동시키기 위하여 여러분은 그것을 모두다 결국에는 이어붙일 필요가 있을 것이다.
주의할 첫 번째 사항은 상단부의 주석이다. 이것은 일반적인 관습으로 그 파일을 읽는 독자가 그 파일이 무엇을 담고 있으며 어떻게 쓰여져야 하는지에 대하여 이해할 수 있도록 해준다. 비슷한 시기의 최신 버전을 사용하고 있는 다른 사람과 결과를 비교할때 버전 정보(저자와 날짜) 역시 유용하다.
마지막 섹션은 "__main__" 명령어 라인에서 적재된 어떤 모듈이라도 호출하는 파이썬의 능력이다. 우리는 특별한, 내장 __name__ 변수를 테스트할 수 있으며 만약 그것이 main 이라면 우리는 그 모듈이 단순히 수입되는 것이 아니라 실행된다는 것을 안다. 그래서 우리는 그 촉발코드를 if 안에서 실행한다.
이러한 촉발 코드는 아무런 파일이름이 주어지지 않거나 혹은 실제로 너무 많은 파일이름이 주어진다면 그 프로그램이 어떻게 실행되어야 하는지에 관하여 사용자 우호적인 힌트를 담고 있다.
마지막으로 주목할 것은 Analyze() 함수는 단순하게 다른 함수들을 오른쪽 순서로 호출한다는 것이다. 또 다시 이것은 아주 흔한 관례로서 사용자가 간단한 방법으로 (Analyze()를 통하여) 그 기능의 모든 것을 사용하도록 선택할 수 있게 해주거나, 혹은 저 수준의 원시 primitive 함수를 직접 호출하는것을 선택하도록 해준다.
foreach line in file:
increment line count
if line empty:
increment paragraph count
split line into character groups
우리는 이것을 파이썬으로 별 다른 노력없이 구현할 수 있다:
# use global counter variables and list of char groups def getCharGroups(infile): global para_count, line_count, groups try: for line in infile.readlines(): line_count = line_count + 1 if len(line) == 1: # only newline => para break para_count = para_count + 1 else: groups = groups + string.split(line) except: print "Failed to read file ", sys.argv[1] sys.exit()주 의 1: 우리는 여기에서 global 키워드를 사용하여 그 함수 밖에 생성되도록 변수들을 선언해야만 한다. 만약 우리가 그것들에 할당할 때 그렇게 하지 않았다면 파이썬은 이 함수에 대하여 똑 같은 이름의 지역적인local 새로운 변수들을 생성할 것이다. 이러한 지역 변수를 변경하는 것은 모듈(혹은 전역global) 수준의 값들에는 영향을 미치지 않을 것이다.
주 의 2: 우리는 여기에서 try/except절을 사용하여 에러들을 낚아채어 그 잘못을 보고하고 프로그램을 종료하였다.
이것은 약간 더 노력을 필요로 하며 파이썬의 새로운 사양 몇몇을 사용한다.
의사 코드는 다음과 같다:
foreach character group:
increment group count
extract punctuation chars into a dictionary - {char:count}
if no chars left:
delete group
else: increment word count
나의 첫 번째 시도는 다음과 같이 보일 것이다:
def getPunctuation(wordList):
global punctuation_counts
for item in wordList:
while item and (item[-1] not in alphas):
p = item[-1]
item = item[:-1]
if p in punctuation_counts.keys():
punctuation_counts[p] = punctuation_counts[p] + 1
else: punctuation_counts[p] = 1
주목할 것은 이것은 의사 코드 버젼의 마지막 절인 if/else을 포함하지 않는다는 것이다.
나는 간결하게 하기 위하여 그것을 생략했다 그리고 실제로 오직 구두점 문자만 담고 있는 단어는 거의 발견되지 않을 것이라고 생각했기 때문이다.
그렇지만 우리는 그것을 그 코드의 마지막 버전에 추가할 것이다.
주 의 1: 우리는 wordList를 매개변수화 했으므로 그래서 그 모듈을 사용하는 사람은 파일로부터 일하도록 강제되기 보다는 그들 자신만의 리스트를 공급할수 있다.
주 의 2: 우리는 item[:-1]을 item에 할당했다. 이것은 파이썬에서 조각썰기 slicing로 알려져 있으며 콜론은 단순히 그 지표를 범위로 취급한다는 것을 말해준다. 예를 들어 우리가 item[3:6]를 지정한다면 item[3}, item[4] 그리고 item[5] 를 리스트로 추출한다.
기본 범위는 콜론이 공백인 쪽이 어느쪽이냐에 따라서 리스트의 시작 혹은 끝이다 그리하여 item[3:]는 item[3]에서부터 마지막까지의 항목 모든 구성원을 뜻할 것이다. 또한 이것은 대단히 유용한 파이썬의 사양이다. 원래의 item 리스트는 (그리고 적당한 시기에 쓰레기 수집이 되어) 사라지고 새로이 생성된 리스트는 item에 할당된다.
주 의 3: 우리는 음의 지표를 사용하여 item로부터 마지막 문자를 추출할 수 있다. 이것은 대단히 유용한 파이썬의 사양이다. 또한 그룹의 마지막에 다중 구두점 문자들이 있는 경우에는 우리는 회돌이를 한다.
이것을 테스트하는 도중에 우리는 그룹의 앞에서 역시 같은 일을 할 필요가 있다는 것이 명료해진다. 왜냐하면 닫는 각괄호가 감지되었음에도 불구하고 여는 각괄호가 없기때문이다! 이 문제를 극복하기 위해서 나는 새로운 함수 trim()를 만들 것이다. 그것은 개별적인 문자그룹의 앞과 뒤로부터 구두점을 제거할 것이다:
#########################################################
# Note trim uses recursion where the terminating condition
# is either 0 or -1. An "InvalidEnd" error is raised for
# anything other than -1, 0 or 2.
##########################################################
def trim(item,end = 2):
""" remove non alphas from left(0), right(-1) or both ends of item"""
if end not in [0,-1,2]:
raise "InvalidEnd"
if end == 2:
trim(item, 0)
trim(item, -1)
else:
while (len(item) > 0) and (item[end] not in alphas):
ch = item[end]
if ch in punctuation_counts.keys():
punctuation_counts[ch] = punctuation_counts[ch] + 1
if end == 0: item = item[1:]
if end == -1: item = item[:-1]
주목할 것은 되부름을 결합한 사용법으로 하나의 매개변수를 기본설정함으로써 우리는 한개의 trim 함수를 정의할 수 있고 그 함수는 기본으로 양쪽끝을 다듬는다, 그러나 (매개변수에) 넘겨받음으로써 마지막 값은 오로지 한 쪽의 끝 만을 처리하도록 만들어질 수 있다.
마지막 값은 파이썬의 지표화 시스템을 반영하여 선택된다 : 0 은 왼쪽 끝이고 -1 은 오른쪽 끝이다.
나는 원래 두 개의 trim 함수를 각각에 대하여 하나씩, 작성했는데, 그러나 너무도 많이 비슷해서 나는 그것들을 매개변수를 사용하여 결합할 수 있음을 깨닫았다.
그러면 getPuntuation함수는 거의 시시하게 된다:
def getPunctuation(wordList):
for item in wordList:
trim(item)
# Now delete any empty 'words'
for i in range(len(wordList)):
if len(wordList[i]) == 0:
del(wordList[i])
주 의 1: 이것은 이제 공백 단어의 삭제를 포함한다.
주 의 2: 재사용의 관점에서 우리는 trim을 더 잘 다듬어서 역시 더 작은 것으로 만드는 것이 더 좋았을지도 모른다. 이것으로 우리는 한 단어의 앞 혹은 뒤로부터 한개의 구두점을 제거하고 제거된 문자를 반환하는 함수를 만들수 있었을 것이다. 그러면 또 다른 함수는 그 함수를 반복적으로 호출하여 최종결과를 획득했을 것이다. 그렇지만 우리의 모듈은 실제로는 일반적인 텍스트를 생성하는 것이 아니라 텍스트로부터 통계를 산출하는 것이므로 그것을 처리하기 위해서는 우리가 그것을 수입할 수 있도록 적절히 분리된 별개의 모듈로 만드는 것을 포함했어야 한다. 그러나 그것 역시 그렇게 유용해 보이지 않는 단 한개의 함수만을 가지므로 그래서 나는 그것을 그대로 두기로 했다!
남아있는 유일한 문제는 구두점 문자와 그 개수를 포함하도록 보고를 개선하는 것이다. 존재하는 reportStats() 함수를 다음과 같이 바꾸어라:
def reportStats():
global sentence_count, clause_count
for p in stop_tokens:
sentence_count = sentence_count + punctuation_counts[p]
for c in punctuation_counts.keys():
clause_count = clause_count + punctuation_counts[c]
print format % (sys.argv[1],
para_count, line_count, sentence_count,
clause_count, len(groups))
print "The following punctuation characters were used:"
for p in punctuation_counts.keys():
print "\t%s\t:\t%3d" % (p, punctuation_counts[p])
여러분이 주의깊게 위의 모든 함수들을 적당한 곳에 꿰어 맞추면 여러분은 이제 다음과 같이 타이프할 수 있을 것이다.:
C:> python grammar.py myfile.txt그리고 여러분의 파일 myfile.txt 에대한(혹은 그것이 실제로 무엇으로 불리든지) 통계를 보고 받는다. 이것이 여러분에게 얼마나 유용한지는 논쟁의 여지가 있으나 희망적이게도 그 코드의 진화과정을 읽는 것은 여러분이 여러분 자신만의 프로그램을 작성하는 법에 대한 어떤 아이디어를 가질 수 있도록 도와 준다. 중요한 것은 열심히 시도해 보는 것이다. 여러가지 접근법을 시도해 보는 것이 창피한 것이 아니다, 때로 여러분은 그 과정에서 가치있는 교훈을 얻는다.
우리의 강좌를 결론지으려면 우리는 문법 모듈을 재 작업하여 OO 기술을 사용하도록 해야 할 것이다. 그렇게 하는 동안에 여러분은 OO 접근법이 어떻게 사용자에게 더욱 더 유연하고, 또한 더욱 확장가능한 모듈을 결과로 하는지 보게 될 것이다.
우리의 모듈에서 사용자에게 가장 커다란 문제중의 하나는 전역 변수에 의존하는 것이다. 이것이 뜻하는 바는 그것은 오직 한번에 하나의 문서만을 분석할 수 있다는 것을 의미하는데, 더 많이 처리하려는 어떤 시도도 그 전역 변수들이 덮어쓰여지는 결과가 될 것이다.
이러한 전역변수들을 클래스로 이동시키므로써 우리는 그러면 ( 파일당 한개씩) 그 클래스의 다중 실체를 만들 수 있다. 그리고 각 실체는 자기 자신만의 변수 집합을 가진다. 게다가, 메쏘드를 충분히 작게 알갱이화함으로써 우리는 아키텍쳐를 만들 수 있다. 거기에서는 새로운 형의 문서 객체를 만든 자가 검색 기준을 변경하여 (예를 들어, 모든 HTML 태그들을 단어의 리스트로부터 제거함으로써) 새로운 형의 규칙에 부합하도록 하는 것은 쉬운 일이다.
이것에 대한 우리의 첫번째 시도는 다음과 같다:
#! /usr/local/bin/python ################################ # Module: document.py # Author: A.J. Gauld # Date: 2000/08/12 # Version: 2.0 ################################ # This module provides a Document class which # can be subclassed for different categories of # Document(text, HTML, Latex etc). Text and HTML are # provided as samples. # # Primary services available include # - getCharGroups(), # - getWords(), # - reportStats(). ################################ import sys,string class Document: def __init__(self, filename): self.filename = filename self.para_count = 1 self.line_count, self.sentence_count, self.clause_count, self.word_count = 0,0,0,0 self.alphas = string.letters + string.digits self.stop_tokens = ['.','?','!'] self.punctuation_chars = ['&','(',')','-',';',':',','] + self.stop_tokens self.lines = [] self.groups = [] self.punctuation_counts = {} for c in self.punctuation_chars + self.stop_tokens: self.punctuation_counts[c] = 0 self.format = """%s contains: %d paragraphs, %d lines and %d sentences. These in turn contain %d clauses and a total of %d words.""" def getLines(self): try: self.infile = open(self.filename,"r") self.lines = self.infile.readlines() except: print "Failed to read file ",self.filename sys.exit() def getCharGroups(self, lines): for line in lines: line = line[:-1] # lose the '\n' at the end self.line_count = self.line_count + 1 if len(line) == 0: # empty => para break self.para_count = self.para_count + 1 else: self.groups = self.groups + string.split(line) def getWords(self): pass def reportStats(self, paras=1, lines=1, sentences=1, words=1, punc=1): pass def Analyze(self): self.getLines() self.getCharGroups(self.lines) self.getWords() self.reportStats() class TextDocument(Document): pass class HTMLDocument(Document): pass if __name__ == "__main__": if len(sys.argv) != 2: print "Usage: python document.py <filename>" sys.exit() else: D = Document(sys.argv[1]) D.Analyze()
이제 그 클래스를 구현하기 위하여 우리는 getWords 메쏘드를 정의할 필요가 있다. 우리는 단순히 우리가 이전 버전에서 작성한 것을 복사해서 다듬어진 메쏘드를 만들 수 있지만, 우리는 더욱 쉽게 확장가능한 OO 버전을 원하고 그래서 대신에 우리는 getWords 를 일련의 단계별로 쪼갤것이다. 그러면 하부 클래스에서 우리는 전체 getWords 메쏘드가 아니라 오직 그 하부 단계를 덮어쓰기만 하면 된다. 이것은 다른 종류의 문서를 다루기 위한 더 넓은 영역을 허용할 것이다.
특별히 우리는 메쏘드를 추가하여 우리가 유효하지 않다고 인정되는 그룹들을 거부할 것이다, 앞에서부터 그리고 뒤에서부터 원하지 않는 문자를 잘라 내어 버릴 것이다. 그리하여 우리는 Document에 3개의 메쏘드를 추가하고 이러한 메쏘드의 관점에서 getWords를 구현한다.
class Document:
# .... as above
def getWords(self):
for w in self.groups:
self.ltrim(w)
self.rtrim(w)
self.removeExceptions()
def removeExceptions(self):
pass
def ltrim(self,word):
pass
def rtrim(self,word):
pass
그렇지만 기억할 것은 우리가 그 몸체들을 한개의 명령어 pass로 정의한 것이다, 그것은 아무것도 하지 않는 것이다. 그것들 대신에 우리는 이러한 메쏘드가 각각의 구체적인 문서형에 대하여 어떻게 작용해야 하는지를 정의할 것이다.
텍스트 문서는 다음과 같이 보인다:
class TextDocument(Document):
def ltrim(self,word):
while (len(word) > 0) and (word[0] not in self.alphas):
ch = word[0]
if ch in self.c_punctuation.keys():
self.c_punctuation[ch] = self.c_punctuation[ch] + 1
word = word[1:]
return word
def rtrim(self,word):
while (len(word) > 0) and (word[-1] not in self.alphas):
ch = word[-1]
if ch in self.c_punctuation.keys():
self.c_punctuation[ch] = self.c_punctuation[ch] + 1
word = word[:-1]
return word
def removeExceptions(self):
top = len(self.groups)
n = 0
while n < top:
if (len(self.groups[n]) == 0):
del(self.groups[n])
top = top - 1
n = n+1
trim 함수는 실제적으로 우리의 grammar.py 모듈의 trim 함수와 동일하지만, 그러나 두 개로 갈라진다. removeExceptions함수는 공백 단어들을 제거하도록 정의 되어졌다.
주목할 것은 나는 후자의 메쏘드 구조를 변경하여 이전의 for회돌이 대신에 while 회돌이를 사용하였다는 것이다. 이것은 테스트하는 동안에 버그가 발견되었는데 거기에서 우리가 리스트로부터 요소를 삭제했음에도 불구하고 range 는 여전히 (처음에 계산된) 원래의 길이를 가졌으며 우리는 그 리스트의 마지막을 넘어서서 그 리스트의 요소들에 접근하려는 시도를 포기해야 했기 때문이다. 그것을 피하기 위하여 우리는 while 회돌이를 사용하고 우리가 한 요소를 제거할 때마다 최대 지표를 조정한다.
그리하여 HTML 문서는 다음과 같이 보인다:
class HTMLDocument(TextDocument):
def removeExceptions(self):
""" use regular expressions to remove all <.+?> """
import re
tag = re.compile("<.+?>")# use non greedy re
L = 0
while L < len(self.lines):
if len(self.lines[L]) > 1: # if its not blank
self.lines[L] = tag.sub('', self.lines[L])
if len(self.lines[L]) == 1:
del(self.lines[L])
else: L = L+1
else: L = L+1
def getWords(self):
self.removeExceptions()
for i in range(len(self.groups)):
w = self.groups[i]
w = self.ltrim(w)
self.groups[i] = self.rtrim(w)
TextDocument.removeExceptions(self)# now strip empty words
주 의 1: 여기에서 주의할 유일한 것은 다듬기하기전에 self.removeExceptions을 호출하고 그리고 TextDocument.removeExceptions를 호출하는 것이다.
우리가 그 상속된 getWords에 의존했다면 그것은 다듬고 난 후에 우리의 removeExceptions를 호출했을 것이다. 그것은 우리가 원한바가 아니다.
마지막으로 우리는 generateStats()를 호출하도록 Analyze 를 변경할 필요가 있다. 그리고 분석이 끝난후 특별히 printStats()을 호출하도록 전체 흐름을 변경할 필요가 있다. 적절한 곳을 이렇게 변경 하고 나면 그 존재하는 코드는, 적어도 명령어 라인 유저에 관한한, 전과 같이 작업을 잘 수행할 것이다. 다른 프로그래머들은 Analyze 를 사용하고 난 다음에 그들의 코드에 printStats()에 약간의 수정을 가해야만 할 것이다 - 그렇게 힘든 수정은 아니다.
수정된 코드 조각은 다음과 같이 보인다:
def generateStats(self):
self.word_count = len(self.groups)
for c in self.stop_tokens:
self.sentence_count = self.sentence_count + self.punctuation_counts[c]
for c in self.punctuation_counts.keys():
self.clause_count = self.clause_count + self.punctuation_counts[c]
def printStats(self):
print self.format % (self.filename, self.para_count,
self.line_count, self.sentence_count,
self.clause_count, self.word_count)
print "The following punctuation characters were used:"
for i in self.punctuation_counts.keys():
print "\t%s\t:\t%4d" % (i,self.punctuation_counts[i])
and:
if __name__ == "__main__":
if len(sys.argv) != 2:
print "Usage: python document.py <filename>"
sys.exit()
else:
try:
D = HTMLDocument(sys.argv[1])
D.Analyze()
D.printStats()
except:
print "Error analyzing file: %s" % sys.argv[1]
이제 우리는 우리의 문서 클래스 둘레에 구이 싸개를 생성할 준비가 되었다.
첫 번째 단계는 그것이 어떻게 보일지 시각화하려는 시도이다. 우리는 파일이름을 지정할 필요가 있으며, 그래서 그것은 Edit 혹은 Entry 콘트롤을 필요로 할 것이다. 우리는 또한 텍스튜얼한 분석을 원하는지 혹은 HTML 분석을 원하는지 지정해줄 필요가 있다. '다수에서 하나를' 선택하는 이러한 형태는 라디오버튼 콘트롤Radiobutton들의 집합에 의해서 보통 나타내어진다. 이러한 콘트롤들은 함께 그룹화되어서 그들이 서로 관련이 있다는 것을 보여주어야만 한다.
다음의 필요조건은 결과를 여러가지 형태로 출력하기 위한 것이다. 우리는 카운터당 하나씩 다중 라벨 콘트롤을 선택할 수 있었을 것이다. 그 대신에 나는 단순한 텍스트 콘트롤을 사용할 것이다. 거기에 우리는 문자열을 끼워 넣을 수 있다. 이것이 명령어 라인 출력의 철학에 더욱 가깝다. 그러나 궁극적으로 선택은 디자이너의 선호도의 문제이다.
마지막으로 우리는 그 분석을 초기화하고 그 어플리케이션을 종료하는 방법이 필요하다. 우리는 텍스트 콘트롤을 사용하여 결과를 출력할 것이므로 화면을 재설정하는 방법을 가지는 것 역시 유용할 것이다. 이러한 명령어 선택사항은 모두 버튼Button 콘트롤에 의해서 나타내어질 수 있다.
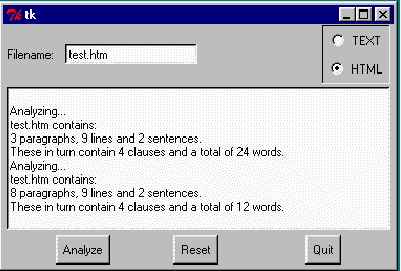
이러한 아이디어를 구이로 대충 그려보면 우리는 다음과 같은 것을 얻게 된다:
+-------------------------+-----------+ | FIILENAME | O TEXT | | | O HTML | +-------------------------+-----------+ | | | | | | | | | | +-------------------------------------+ | | | ANALYZE RESET QUIT | | | +-------------------------------------+
from Tkinter import * import document ################### CLASS DEFINITIONS ###################### class GrammarApp(Frame): def __init__(self, parent=0): Frame.__init__(self,parent) self.type = 2 # create variable with default value self.master.title('Grammar counter') self.buildUI()
여기에 우리는 Tkinter 와 문서(document) 모듈을 수입하였다. 전자를 위해서는 우리는 우리의 현재 모듈안에서 모든 Tkinter 이름이 보여지도록 한 반면에 후자에는 우리는 'document'라는 이름으로 접두사를 붙일 필요가 있을 것이다.
우리는 또한 __init__ 메쏘드를 정의 하였는데 그것은 Frame.__init__ 수퍼 클래스 메쏘드를 호출하여 Tkinter가 내부적으로 적절히 설정되었는지 확인한다. 그리고는 우리는 문서형의 값을 저장하는 속성하나를 만들고 마지막으로 우리를 위한 모든 위젯들을 생성하는 buildUI 메쏘드를 호출한다.
def buildUI(self):
# Now the file information: File name and type
fFile = Frame(self)
Label(fFile, text="Filename: ").pack(side="left")
self.eName = Entry(fFile)
self.eName.insert(INSERT,"test.htm")
self.eName.pack(side="left", padx=5)
# to keep the radio buttons lined up with the
# name we need another frame
fType = Frame(fFile, borderwidth=1, relief=SUNKEN)
self.rText = Radiobutton(fType, text="TEXT",
variable = self.type, value=2,
command=self.doText)
self.rText.pack(side=TOP)
self.rHTML = Radiobutton(fType, text="HTML",
variable=self.type, value=1,
command=self.doHTML)
self.rHTML.pack(side=TOP)
# make TEXT the default selection
self.rText.select()
fType.pack(side="right", padx=3)
fFile.pack(side="top", fill=X)
# the text box holds the output, pad it to give a border
self.txtBox = Text(fApp, width=60, height=10)
self.txtBox.pack(side=TOP, padx=3, pady=3)
# finally put some command buttons on to do the real work
fButts = Frame(self)
self.bAnal = Button(fButts, text="Analyze",
command=self.AnalyzeEvent)
self.bAnal.pack(side=LEFT, anchor=W, padx=50, pady=2)
self.bReset = Button(fButts, text="Reset",
command=self.doReset)
self.bReset.pack(side=LEFT, padx=10)
self.bQuit = Button(fButts, text="Quit",
command=self.doQuitEvent)
self.bQuit.pack(side=RIGHT, anchor=E, padx=50, pady=2)
fButts.pack(side=BOTTOM, fill=X)
self.pack()
나는 이 모든 것을 설명하지는 않겠다, 대신에 나는 여러분 파이썬 웹사이트에 있는 Tkinter 지침서를 살펴보기를 권장한다. 이것은 Tkinter에 대한 훌륭한 개론서이자 참조서이다. 일반적인 원리는 여러분이 위젯들을 그에 상응하는 클래스로 부터 생성하고, 선택사항들을 이름있는 매개변수named parameters로 제공하면, 그러면 그 위젯은 포장되어져packed 그것을 담고 있는 프레임으로 들어간다는 것이다.
기억해야할 다른 주요 요점은 라디오 버튼과 명령어 버튼을 가지고 있는 보조적인 프레임Frame 위젯의 사용법이다. 라디오 버튼은 또한 variable & value라고 불리우는 한 쌍의 선택사항을 가지고 있다. 전자는 같은 외부 변수(self.type) 를 지정하여 라디오 버튼과 함께 링크되고, 후자는 각각의 라디오 버튼에 유일한 값을 제공한다. 또한 버튼 콘트롤로 넘겨지는 command=xxx 선택사항을 주목하라. 이것들은 버튼이 눌려졌을 때 Tkinter에 의해서 불려질 메쏘드들이다. 이것을 위한 코드는 다음에 온다:
################# EVENT HANDLING METHODS #################### # time to die... def doQuitEvent(self): import sys sys.exit() # restore default settings def doReset(self): self.txtBox.delete(1.0, END) self.rText.select() # set radio values def doText(self): self.type = 2 def doHTML(self): self.type = 1
이러한 메쏘드들은 모두 아주 시시하다 그리고 다행스럽게도 지금까지는 그 자체로 설명이 된다. 마지막 사건 처리자는 분석을 하는 처리자이다:
# Create appropriate document type and analyze it.
# then display the results in the form
def AnalyzeEvent(self):
filename = self.eName.get()
if filename == "":
self.txtBox.insert(END,"\nNo filename provided!\n")
return
if self.type == 2:
doc = document.TextDocument(filename)
else:
doc = document.HTMLDocument(filename)
self.txtBox.insert(END, "\nAnalyzing...\n")
doc.Analyze()
str = doc.format % (filename,
doc.c_paragraph, doc.c_line,
doc.c_sentence, doc.c_clause, doc.c_words)
self.txtBox.insert(END, str)
다시 여러분은 이것을 읽고 그것이 무엇을 하는지를 살펴볼수 있어야만 한다 중요한 포인트는 다음과 같다:
지금 필요한 모든 것은 어플리케이션 객체의 실체를 생성하고 사건 회돌이를 설정하는 것이다, 우리가 여기에 이것을 한다면:
myApp = GrammarApp() myApp.mainloop()
MS-윈도우하에서 보여서, 최종 결과를 살펴보자. 테스트용 HTML 파일을 분석한 결과를, 첫 번째는 텍스트 모드로 그리고는 HTML모드로 보여준다:
그것이다. 여러분은 계속해서 HTML 처리과정을 더욱 정밀하게 여러분이 원한다면 만들 수 있다. 여러분은 새로운 모듈을 새로운 문서 형을 위해서 만들 수 있다. 여러분은 텍스트 박스와 프레임으로 포장되어진 다중 라벨과 바꾸려고 시도해 볼 수 있다. 그러나 우리의 목적은 달성했다. 다음 섹션은 여러분의 프로그래밍 열망에 따라서 다음에는 어디로 가야할 지 어떤 아이디어를 제공한다. 가장 중요한 것은 그것을 즐기는 것이다 그리고 항상 기억하라 : 컴퓨터는 바보다!
이 페이지에 대하여 질문 혹은 제안사항이 있으면 다음 주소로 나에게 전자메일을 보내라: agauld@crosswinds.net