What will we cover?
Note: In this topic I refer to a lot of conceptual ideas for which only limited knowledge is required to write the code discussed in the following topics. I try to provide links, mainly to Wikipedia articles, but if there is no link you will find most of the subjects discussed in more depth on Wikipedia.
The story of the world wide web and its invention by Tim Berners-Lee is probably one of the best known in computing. However, it is worth revisiting some of the key points in the story to provide a background to why the web and its technology are the way they are today. The web was invented by Berners-Lee to solve a real problem that he and his colleagues at CERN were experiencing namely, document sharing. They had a large number of documents in various locations and in different formats. Each required understanding of concepts that were explained in other documents. Many were works in progress, being developed by multiple authors. Berners-Lee realised that a techology existed which could greatly ease the situation, it was Hypertext. Hypertext had been around in various forms for many years, in fact the idea pre-dated the invention of the modern computer! There were several Hypertext solutions available on computers when Berners-Lee studied the problem, but they were either expensive and proprietary or only capable of running on a single computer. Berners-Lee's big contribution was to take the idea and put it on a network. This was what enabled the collaboration of many workers at once and the access to many diversely located documents. By making the network access transparent to the user it was as if the library was one gigantic document all cross-linked and seamlessly joined together, truly a world wide web of information.
Berners-Lee had already built a type of hypertext system and he had experience with the internet so it was fairly natural for him to take these two ideas and join them together. In doing so he invented several component parts which together form the web. The Hypertext concept required a mechanism for linking documents together, and so Berners-Lee invented a text formatting, or markup, system which he called HyperText Markup Language (HTML) based on an existing standard called Standard Generalised Markup Language (SGML). All web pages are written in HTML, (or XHTML which is an XML compliant variant of HTML) either by a human author or by a computer program. Web browsers display their pages by interpreting the HTML markup tags and presenting the formatted content. This is not the place to try and teach HTML, so if you don't already know how to create simple HTML documents then I suggest you find a good reference or tutorial, like the one here.
Having defined a markup language Berners-Lee could now create basic hypertext documents, like this tutorial. The pages could be formatted, images inserted and links to other documents created. So far no networking is involved. The next step was to make these documents accessible over the network and to do that required the definition of a standard address format for content. This is the now ubiquitous Uniform Resource Locator or URL. The first part of a URL identifies the protocol to be used, usually http for the web. The next part uses standard internet naming to identify a server (and optional port, the default being 80) and the final part is the logical location of the content on the server. I say logical because, although the specification looks like an absolute directory path in Unix, it is in fact relative to some fixed location known to the server, and indeed may not be a real location at all, since the server may translate the location into an application invocation or other form of data source. So if we look at the full URL of this page it is:
| protocol | IP address | port | location |
|---|---|---|---|
| http:// | www.alan-g.me.uk | :80 | /l2p2/tutweb.htm |
One problem with the static hypertext content that this scheme provided was that it was read-only. There was no way to interact with the content, nor indeed could the content be easily modified. Berners-Lee wanted more, he wanted the ability to interact with the content dynamically.
The solution to providing dynamic content lay in appending data to the end of the URL in what is known as an encoded string or, sometimes, an escaped string. These are the long strings of letters, numbers and percent signs that you sometimes see in the address bar of your browser after visiting a link. We will discuss these strings in more detail later, since to communicate with dynamic web sites we will need to be able to construct these encoded strings.
The ability to interact with the content provided several features. One important advantage was the ability to provide secured access to pages by requiring the user to enter a username and password. Users could be required to register interest in pages before being granted access. And of course the same ability to capture usernames etc. could also be used to capture credit card details and selections from catalogs, and thus internet shopping became possible.
The technology for creating dynamic web content is called the Common Gateway Interface (or CGI). The CGI had the advantage of being very easy to implement and was entirely language neutral. Early CGI based web applications were written in languages as diverse as C and C++ to DOS Batch files and Unix shell scripts, with everything in between. However, it didn't take long for the scripting language Perl to become a favourite, largely due to Perl's built in text handling power and the existence of a powerful CGI library module for handling web requests. As you would expect Python also has a cgi module for building basic dynamic web applications and we will look at that in the web server topic.
This is all very well but it puts all the intelligence and ability to interact with users in the server. To provide a more immediate response it became clear that some kind of programmability was desirable within the browser. This was provided initially by Netscape in the form of JavaScript (and VBScript in Microsoft's Internet Explorer). The scripting works by having the browser build a software model of the document inside its memory. This is called the Document Object Model (DOM) and over many years this has been standardised across browsers. The scripting language can thus search this model for document components (like paragraphs or tables) and modify them, perhaps changing colour or position in the page. This was especially useful for validating user input before sending data to the server.
There is one major snag to standard CGI programming which is that every request requires the web server to create a new process. This is slow and resource hungry, especially on Windows computers. It was only a matter of time therefore before new, more efficient mechanisms were developed that still utilised the CGI protocol but enabled the web servers to handle the requests more efficiently. Nowadays, relatively few web applications are written using basic CGI, and Perl has lost its monopoly as the web language of choice, with technologies like Active Server Pages (ASP), Java Server Pages (JSP), Servlets, PHP and so on becoming dominant. We will look at one such technology based on Python (of course!) in the Web Application Framework topic.
Before we get to writing web applications on the server however, I want to look at the overall architecture of web applications and the various technologies used at each stage. We start by looking at the underlying network protocol that Berners-Lee developed to enable his hypertext clients to talk to the document servers.
Before we can start programming for the web we need a basic understanding of how the web works. And that means looking at the HyperText Transfer Protocol, or http. In essence http is just a string based protocol communicating over sockets in exactly the same way that we did in the Network Programming topic. It provides several messages:
There are a few more but these are the main messages used to build applications, and by far the most common are GET and POST. But you can see that we have the basis of a traditional CRUD lifecycle - Create, Read, Update, Delete
If you followed the http link above you'll see that there is quite a lot to learn to become an expert on http. Fortunately we don't need to be experts and the level of knowledge required to use http is quite low because most of the work is done for us by library modules.
Basically, a web client issues an http GET request. The server then responds either with an error message, for which there are several standard codes, or with an HTML document. It is possible to do all of that manually using sockets and formatted strings. But a much easier method is to use the urllib package provided in the Python standard library. More specifically we need the urllib.requests module which handles sending requests to the server.
The sequence of steps to fetch a basic web page is very simple. All you need is to import urllib.request then open a url and read the result. Like this:
>>> import urllib.request as url
>>> site = url.urlopen('http://www.alan-g.me.uk/l2p2/index.htm')
>>> page = site.read()
>>> print( page )
That really is all that's required. You now have a string containing all the HTML for the tutor homepage. You can compare it, if you like, with the effects of using View->Source from your browser. Apart from the fact that the browser formats the HTML to make it more readable it is exactly the same content. The next question is, what to do with the content now that we have it? We need to parse it to extract the information we need. At its simplest level parsing just involves searching for a specific string or regular expression. For example, you could find all of the image tags in a page by searching for the string '<img' or '<IMG' or the regular expression '<img' with the re.IGNORECASE flag set. In practice, however, there are usually a few additional obstacles to deal with and we will look at some practical examples in the next topic Writing Web Clients
Before we look at parsing HTML however, we should look at the bigger picture of how web applications are built. There are several layers involved and each uses its own technology set. One of the most notable features of the Web for the programmer is that you need to learn an awful lot of different languages to build anything significant, and Python is just one part of the overall solution.
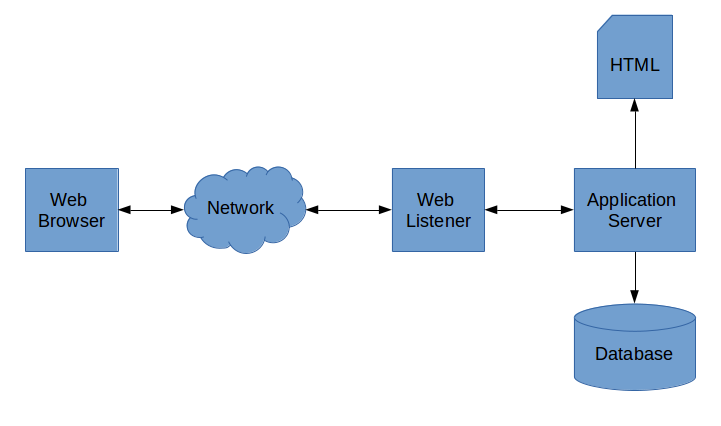
A classical web application starts with a web browser running in a client computer sending a request over the network to a server somewhere. The server runs a piece of software called a web server or, sometimes a web listener. The web listener detects requests and, if they are valid, sends them to an application server, which may or may not be part of the web server installation. It may even be on a separate computer within the data-center. The application server interprets the received message and either returns a static HTML file from its file system or it processes the received data and generates a new HTML document on demand, possibly with the help of data stored in a database. In either case the HTML is sent back to the browser where it is received by the browser and interpreted and rendered onto the users screen as a formatted web page.
The technologies used in each stage are quite different. Let's now consider each building block in turn.
From that you can see that to build a complete web application you need to learn about: HTML, CSS, JavaScript, Python, and SQL as well as how to configure and administer the various servers. Phew! In practice web developers tend to gravitate to either frontend development (the HTML/CSS/JavaScript bits) or backend development using Python (or any of the other popular web development languages such as Java, PHP or Ruby) and SQL. To make this split easier various templating mechanisms have been devised where a graphic designer can design the web pages and leave markers in the code that the frontend and backend programmers can attach their data. This separation of concerns means that arty graphics designers don't need to know much about the technology and the geeky developers don't need to worry about the arty design stuff. Everyone is happy.
Over the next two topics we look at both client and server side web programming. In the first case how to process HTML as if we were a browser. This is often necessary if we want to build up a database of information obtained from the web. For example you might get data from two different web sites and want to combine it together to analyse trends or some such. This is known as client side programming.
Server side programming is where we create an actual web site with dynamic content. We will look at how this is done using traditional CGI because understanding the underlying technology is helpful in working with more advanced frameworks later. We'll then look at one modern web framework, Flask, which is very lightweight and easy to learn but still powerful enough to build significant application functionality. We will finish by migrating our long running address book application onto the web.
Things to remember