What will we cover?
Caveat: The material in this topic uses the os.fork() function which is not available under Microsoft Windows. (One reason is that Windows, compared to Unix, is very slow to create new processes so that in practice you would never use fork() even if you could! There is another solution to this problem - threading - that works on both Unix and Windows which we will cover in a later topic.) If you are using Windows I recommend that you read the concept sections at the top because the principles will be used in the next topic. But there is no point in typing in the examples as they will not work. If you are using any form of Unix, including MacOS X then it should all work as advertised.
As the name suggests Inter-Process communications or IPC, is the mechanism whereby one process can communicate, that is, exchange data, with another process. You will recall if you read the Using the Operating System topic that a process is an executing program. Also that one process can communicate to another using the subprocess module's features. While these techniques are very useful for communicating with other programs they do not provide the fine grained control that's sometimes needed for larger scale applications. In these applications it is quite common for several processes to be used, each performing a dedicated task and other processes requesting services from them.
As an example a web server might have one process for listening to web requests from browsers and serving up simple HTML but use another process for serving more complex data queries, and possibly yet another process for handling ftp requests and the like. Each process is tuned to perform one job well. In addition this architecture allows the administrator to share the processing load over several processes so that if there are a lot of ftp requests a second ftp process can be started and the ftp requests distributed between the two processes.
While you might not expect to be writing such large scale applications it can still be a useful technique and the principles involved are important in many of the later topics we will discuss such as network programming. Even quite small applications can benefit from this approach particularly where there could be many users accessing a common resource, such as a database. Also, if you are reading data from various communications ports, it is useful to have a process per network connection so that blockages in one network do not prevent the other networks from being read.
You may have heard the term client/server being bandied around and this is a very common software architecture for business applications. Client/Server refers to a very specific type of IPC arrangement whereby one process, the client, makes requests of another process, the server. The server never requests anything from the client. There can be many client processes accessing a single server. Servers can in turn be clients to other servers - this is known as N-Tier Client/Server computing.
So client/server computing always uses IPC but IPC is not always client/server based. It is quite possible to have a network of processes each sending messages to the others without any rigid demarcation between clients and servers, this is often called peer to peer computing, While it may sound like an attractive model it turns out to be quite difficult to manage beyond a very small number of processes and the more rigid client/server approach is generally easier to design and operate.
The description of client/server above is all about software and processes. But you may have heard those terms, especially "server" being applied to hardware too, usually in reference to powerful, shared computers. This is a slight abuse of the true meaning of client/server computing which is a purely software architecture and independent of the hardware. But, in practice, server processes tend to run on separate, powerful computers and historically the combination of hardware (combined with server processes) have been referred to as "the server". That style of client/server deployment takes us into the realm of network computing which we look at in the next topic.
You may have noticed a similarity in terminology to Object Oriented Programming with the use of messages between processes being similar to the sending of messages between objects. It turns out that there is indeed a lot of synergy between an object model and an IPC model and some IPC architectures have developed that capitalize on these synergies. One such architecture is the Common Object Request Broker Architecture or CORBA. In this architecture we can register objects with a central Object Request Broker or ORB and messages sent to the object from anywhere in the architecture get routed to whichever process registered the object. We will not be looking at CORBA in this tutorial but there are Python implementations of ORBs that you can investigate if you are interested.
We're nearly ready to start writing some code. There are several different mechanisms for communicating between processes and we will consider two of them. The first IPC mechanism we are going to look at uses a mechanism called a pipe, used to exchange data between the two processes.
Conceptually a pipe can be thought of much like a hose-pipe, in that it is a conduit where we pour data in at one end and it flows out at the other. A pipe looks a lot like a file in that it is treated as a sequential data stream. Unlike a file, a pipe has two ends, so when we create a pipe we get two end points back in return. We can write to one end point and read from the other. Also unlike a file, there is no physical storage of data when we close a pipe, anything that was written in one end but not read out from the other end will be lost.
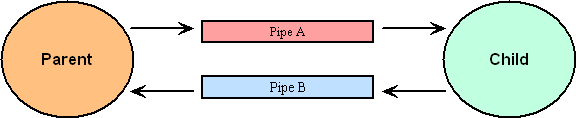
We can illustrate the use of pipes as conduits between processes in the following diagram:
Here we see two processes which I've called Parent and Child, for reasons that will become apparent shortly. The Parent can write to Pipe A. and read from Pipe B. The Child can read from Pipe A and write to Pipe B.
Note that each pipe can be used to send a request or return data depending upon which process is initiating the transaction. This gives us an interesting challenge in naming the pipes which we'll discuss a little later.
OK, enough theory, let's roll up our sleeves, write some code and see how we can build an IPC mechanism using Python. The general idea is that we will create a parent process which will open two pipes. We then fork (or spawn) off a clone of the process, the child, which is an exact copy of the parent process, including the same two pipes. We can then use the pipes to communicate between parent and child.
The first thing to do is see how we use pipes to send and receive data. We create a pipe using the os.pipe() function which returns two file descriptors, one for each end of the pipe. We can then use the os.read/write functions to send data along the pipe. :
import os # create the pipe receive, transmit = os.pipe() data = 'Here is a data string' length = os.write(transmit, bytes(data, 'utf8')) print('Length of data sent: ', length) # 1024 size buffer to ensure all data received print( 'The pipe contains:', os.read(receive, 1024).decode('utf8') )
Note that in common with most system level operations we need to convert the data to/from byte arrays.
Of course this is all happening within a single process so it's not really very useful. But once we clone our process we can separate the reading and writing code and really start to achieve something. So how do we create our clone process?
The mechanism used for spawning a child process is to use the os.fork() system call. This returns different values depending on whether you are in the original, parent process or in the new child process. In the original process the returned value is the process ID or pid of the child process. If you are in the child process then the return value from fork is zero.
This means that in the code we will have an if statement that tests the fork() return value and if it is zero performs the child functions and if non zero does the parent function. To keep things manageable it is usually best to put those functions into separate modules and call the functions as required. In our example here we won't do that since the code is short and a single listing will suffice. (Again I stress that Microsoft Windows does not support the fork() function so the code will not work under Windows. Windows users will need to wait till the next topic to find out how to write client-server programs, sorry, but complain to Microsoft not me!)
What we are going to do is create a child process that can perform a simple text formatting operation for us, it will return the value that we pass to it prefixed and postfixed with the phrase 'Ni'.
Here we go:
import os,signal # create pipes ServerReceive,ClientSend = os.pipe() ClientReceive, ServerSend = os.pipe() pid = os.fork() if pid == 0: # in child while True: # serve forever data = os.read(ServerReceive,1024) if data: # check we received something! data = 'Ni!\n' + data + '\nNi!' else: data = "Error: received empty message" os.write(ServerSend,data) else: # in parent data = ['The Knights who say Ni!', 'Appear in the film "Monty Python and the Holy Grail" '] for line in data: os.write(ClientSend,line) print os.read(ClientReceive,1024) # now terminate the child process os.kill(pid,signal.SIGTERM)
Note that we use the pid received from fork to terminate the child process. If we failed to do this the child would become a background or daemon process running silently, forever waiting for data to appear on its input pipe. The actual termination is done using the os.kill() function which, despite the name, is actually used to send any signal to any process. Signal SIGTERM is the terminate signal as defined in the signal module. The full list is platform dependent and definitively documented in the documentation for the libc C library for your platform, but it is more easily obtained by using
>>> dir(signal)
at the Python interactive prompt or, on a Unix system, by typing:
$ kill -l
at the operating system prompt (Note, that's an 'ell' not a one). In the latter case you also get the numeric value which can be used in kill() directly but at the risk of losing platform independence.
Let's review what we have done: So far we have created pipes, and transmitted data along them. We have spawned a child process, sent data to it, manipulated the data in the child process and sent data back to the parent. Finally, we terminated the child process. That's really all you need for basic IPC, the complexity of the processing is simply a matter of writing more complex functions for the child. So let's see a real example in action. It's time to revisit the address book again.
Back in the files topic we built a version of our address book using a dictionary. Let's reuse that example but this time we will build a client/server version.
Notice that the original code broke one of the good practice rules we discussed earlier: I included User Interface code in my helper functions. If we were to try to use this code we would get messages from the child process mixed up with messages from the parent. We need to tweak the code slightly so that we can turn it into a reusable module. The main thing is to remove any print statements from the functions and pass the data in as arguments. We also want to return a result from each function.
Once we have done that we can import the code and access the helper functions without executing the main() function. The functions that we will make available are therefore:
The modified code looks like this:
def readBook(filename='addbook.dat'):
import os
book = {}
if os.path.exists(filename):
store = open(filename,'r')
for line in store:
name,entry = line.strip().split(':')
book[name] = entry
else:
store = open(filename,'w') # create new empty file
store.close()
return book
def saveBook(book, filename = "addbook.dat"):
store = open(filename,'w')
for name,entry in book.items():
line = "%s:%s" % (name,entry)
store.write(line + '\n')
store.close()
def addEntry(book, name, data):
book[name] = data
return 'Added entry for ' + name
def removeEntry(book, name):
del(book[name])
return 'Deleted entry for ' + name
def findEntry(book, name):
if name in book.keys():
result = "%s : %s" % (name, book[name])
else: result = "Sorry, no entry for: " + name
return result
Note that I've ignored the user interface functions because we don't need them here but you might want to try making the necessary modifications to allow it to still function as a standalone program, as well as serve as a module for the client/server version, as an exercise.
Once you've fixed up the code and got it working as a stand-alone program once more (or just saved the code above as address_srv.py, which is what I've done), we can proceed to writing our client/server code.
The client/server code will comprise our standard structure of creating pipes and forking the process. In the child process we will read the incoming pipe and interpret the data as a command followed by the arguments supplied and then call the relevant database function. In the parent, or client process, we will present the user with a menu and depending on the choice, request any needed additional data before sending the combined data string to the child or server process. The client will then read back the response and present it to the user.
The main program looks like this:
import os, signal, address_srv fromClient,toServer = os.pipe() fromServer,toClient = os.pipe() pid = os.fork() if pid == 0: # we are the server addresses = address_srv.readBook() while True: s = os.read(fromClient,1024) cmd,data = s.split(':') if cmd == "add": details = data.split(',') name = details[0] entry = ','.join(details[1:]) s = address_srv.addEntry(addresses, name, entry) address_srv.saveBook(addresses) elif cmd == "rem": s = address_srv.removeEntry(addresses, data) address_srv.saveBook(addresses) elif cmd == "fnd": s = address_srv.findEntry(addresses, data) else: s = "ERROR: Unrecognized command: " + cmd os.write(toClient,s) else: # We are the client menu = ''' 1) Add Entry 2) Delete Entry 3) Find Entry 4) Quit ''' while True: print( menu ) try: choice = int(input('Choose an option[1-4] ')) except: continue if choice == 1: name = input('Enter the name: ') num = input('Enter the House number: ') street= input('Enter the Street name: ') town = input('Enter the Town: ') phone = input('Enter the Phone number: ') data = "%s,%s,%s,%s,%s" % (name,num,street,town,phone) cmd = "add:%s" % data elif choice == 2: name = input('Enter the name: ') cmd = 'rem:%s' % name elif choice == 3: name = input('Enter the name: ') cmd = 'fnd:%s' % name elif choice == 4: break else: print( "Invalid choice, must be between 1 and 4." ) continue os.write(toServer, cmd) print( "\nRESULT: ", os.read(fromServer,1024) ) os.kill(pid, signal.SIGTERM)
Obviously we could tidy that up a bit more by using some functions for the if/elif chains but the example is small enough for that not to be necessary. A couple of points to note are the use of break to stop the loop and continue to go round to the top of the loop again. We briefly discussed these in the branching topic and hopefully their use is obvious, but if not, the documentation describes them in more detail.
An obvious extension to this exercise would be to use the database version of the address book as the server instead of the dictionary version. I'll leave that as an exercise for the keen students among you!
The big snag with this form of client/server programming is that the server can only talk to the client that started it. (Although its not that hard to create a mechanism whereby we spawn extra processes that recognise that they should act as clients rather than servers). It would be much better if the server could be started first and then multiple clients attach to it. That's exactly what we will do at the end of the next topic where we introduce networking.